

알고리즘의 복잡도
알고리즘(algorithm)
어떤 문제를 정해진 순서에 따라서 해결하는 공식이다. 프로그래밍에서 컴퓨터에게 명령을 내릴 때 전체적인 작업 처리의 순서 등의 설계가 알고리즘으로 볼 수 있다.
거창해보이지만 우리의 일상에서도 흔하게 접할 수 있는 개념이라고 생각한다.
등교해서 시간표대로 흘러가는 수업이나 방학 때 만드는 생활 계획표 등 하루의 전체적인 부분일 수 도 있고 즉석 식품의 조리순서를 보고 만들거나 라면을 끓이는 순서 등 소소한 부분까지도 알고리즘의 영역이라고 볼 수 있다.
알고리즘의 비교
알고리즘을 비교하는 기준으로는 크게 시간 복잡도와 공간 복잡도가 있다.
-
시간 복잡도(time complexity)
알고리즘이 연산을 하는데 걸리는 시간을 의미한다. -
공간 복잡도(space complexity) 프로그램이 차지하는 메모리 공간을 의미한다.
최근에는 컴퓨터가 발전하면서 메모리가 부족한 문제는 거의 없기 때문에 공간 복잡도의 중요성은 예전에 비해 많이 낮아졌지만 프로그램의 속도는 여전히 중요한 부분이고 이와 연관된 시간 복잡도가 공간 복잡도 보다 우선시된다.
알고리즘 속도 측정
자원 사용량
목적지를 모두 순회하는 경로를 짠다고 할 때 최종 목적지에 도달하는 과정에서 어떻게 경로를 순회하는게 효율적인지가 중요하다.
프로그램도 마찬가지로 똑같은 결과를 도출한다고 해도 알고리즘 내부에서 어떤식으로 자료 구조로 만들어야 더 나은 성능과 효율을 낼 것인지가 중요하다.
어떤 알고리즘을 사용하는게 나은지 비교하고 판단하는데 있어서 가장 직관적인 방법은 수행 속도를 측정하는 것이겠지만 이는 일반적인 기준으로 삼기에는 부적합하다.
그 이유는 효율적인 경로를 산책하는 일반인과 비효율적인 경로를 전력질주 하는 육상선수의 수행시간을 비교한다고 했을 때 더 이상 경로의 비교가 의미가 없어지는 것처럼 프로그램 역시 어떤 환경에서 실행되느냐에 따라서 그 속도에서 차이가 발생하기 때문이다.
- 실행 시간
실행시간은 크게 실행환경에 따라 달라진다. (하드웨어, 운영체제, 언어, 컴파일러 등의 요소)
따라서 알고리즘을 비교할 때는 전체적인 실행 시간이 아닌 알고리즘에서 연산을 하는데 걸리는 시간 즉 입력값 당 연산 처리 속도가 기준이 된다.
점근적 표기법(asymptotic notation)
함수의 증가 양상을 다른 함수와의 비교로 표현하는 방법이다.
점근적이란 점점 가까워 진다는 뜻이다.
함수 f(n) = 2n + 1이 있을 때 n이 무한대에 가까워진다면 함수에서 최고차항만을 남기고 계수와 다른 항을 생략한 함수 n은 원본 함수 2n + 1에 한없이 가까워지게 된다.
이렇게 함수를 생략해서 표현하는 것을 점근적 표기법이라고 한다.
알고리즘의 시간 복잡도는 정확한 값은 크게 중요하지 않고 그 비율이 어떻게 증가하는지가 중요하다 이를 성장률(rate of growth)이라고 하며 점근적 표기법으로 시간 복잡도를 표기해 이 성장률을 얻어낼 수 있다.
성장률이 높을 수 록 실행시간이 길어지므로 알고리즘의 속도가 느려진다고 할 수 있다.
예)
입력값 n, 시간 복잡도 f(n)
f(n) = 2n + 1 -> n
f(n) = 2n2 + 2n + 1 -> n2
점근적 표기법 중에서 알고리즘의 복잡도를 나타내는 방식으로는 대표적으로 3가지가 쓰인다.
-
점근적 상한(asymptotic upper bound, O(Big-O))
-
점근적 하한(asymptotic lower bound, Ω(Omega))
-
점근적 상한과 하한의 교집합(asymptotically tight bound, Θ(Theta))
이 중 점근적 상한, 빅 오 표기법이 가장 많이 쓰이는 방법이다.
빅 오 표기법(Big-O notation)
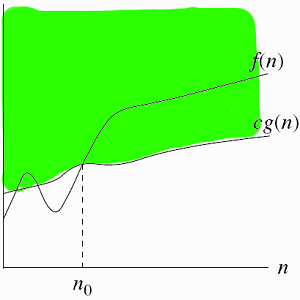
함수 f(n)과 g(n)이 모든 n ≥ n0 에서 f(n) ≤ c·g(n) 조건을 만족시키는 양의 상수 c > 0 와 양의 정수 n0 ≥ 0 이 존재한다면 f(n) ∈ O(g(n)) 또는 f(n) = O(g(n))로 쓸 수 있다.
.png)
그래프를 보면 n0 를 기점으로 알고리즘의 복잡도인 f(n)은 n이 아무리 커져도 즉, 최악의 경우에도 c·g(n)의 실행 속도 보다 길어지는 길어지는 경우가 없으므로 c·g(n)은 f(n)의 점근적 상한이 된다.
이 처럼 빅 오 표기법에서는 복잡도의 증가 속도에 따라서 7가지 함수들을 사용한다.
.jpg)
-
O(1) 상수시간(constant time)
입력값의 크기에 영향을 받지 않고 정해진 값을 가진다면 상수 시간 알고리즘이라고 한다.
// 값을 대입하는 경우 int number = 12345678; // 작동횟수가 일정한 경우 int addUpToNumber(int n) { return n * (n + 1) / 2; } addUpToNumber(10);가장 빠른 속도를 나타낸다.
-
O(n) 선형 시간(linear time)
입력이 증가하면 처리 시간 또한 선형적으로 증가한다. 입력값에 따라 처리하는 작업이 1:1인 경우이다. 일반적으로 반복문의 알고리즘 시간으로 n 번 반복할 때 O(n)의 시간이 걸리며 반복문이 x개라면 O(n * x)의 시간이 걸리지만 여전히 시간 복잡성은 n에 비례하여 증가한다.
for (int i = 0; i < n; i++) { //... } -
O(n²) 2차 시간(quadratic time)
이중 반복문의 경우가 해당된다.
입력값 만큼 반복하는 반복문 안에 또 반복문이 있는 경우for (int i = 0; i < n; i++) { for (int j = 0; j < i + 1; j++) { // ... } }입력값 n이 주어졌을 때 n까지 진행되는 반복문 안에서 또 n만큼의 반복이 진행되는 경우이다.
O(n2) 부터 실행 시간이 급속도로 증가하기 때문에 가능하다면 다른 알고리즘으로 바꾸는게 권장된다.
-
O(log n) 로그 시간(log time)
주로 정렬 알고리즘에서 볼 수있는 시간 복잡도 이다.
로그 시간이 나오는 더 근본적인 이유는 이진 트리를 사용하는데 있다.만약 2개의 자식을 가지는 이진 트리를 이용해서 m개의 값들 중 원하는 값을 찾는 경우일에 처음에는 m개의 모든 값들이 탐색 대상이지만 루트 노드에서 첫 번째 자식 노드 층으로 이동하게 되면 그 수가 절반으로 줄게 되면서 m / 2개의 값들이 남기된다. 그리고 다시 다음 자식 노드층으로 넘어가면 m / 4 개의 값이 남게 되며 이런식으로 노드층 마다 남은 값의 절반이 남게되며 이 시간 복잡도는 로그 함수 logmn로 표현된다.
// 입력값 len bool BinarySearch(int *arr, int len, int key) { int start = 0; int end = len-1; int mid; while(end - start >= 0) { //중앙 값 mid = (start + end) / 2; if (arr[mid] == key) { //key값을 찾았을때 return true; } else if (arr[mid] > key) { //key값이 mid의 값보다 작을때 (왼쪽으로) end = mid - 1; } else { //key값이 mid의 값보다 클때 (오른쪽으로) start = mid + 1; } } return false; }로그 시간은 상수 시간 바로 위에 있으며 빠른 속도라 할 수 있다.
-
O(n log n) 선형 시간(linearithmic time)
이중 반복문의 비효율적인 O(n2) 시간을 해결하기 위한 방법으로 병합 정렬(Merge Sort)을 사용한다.
병합 정렬은 정렬되지 않은 배열을 절반으로 잘라 비슷한 크기의 두 배열로 나누고 이 작업을 각 배열의 크기가 0이 될 때까지 반복한다.
0이 되면 각 부분을 재귀적으로 병합하는 과정을 수행하는데 이 때 합치는 과정에서 실질적으로 정렬이 이루어진다.
이 작업은 크게 세 단계로 나눌 수 있다.
-
분할 : 입력 배열을 같은 크기인 2개의 배열로 분할한다.
-
정복 : 부분 배열을 정리한다. 부분 배열의 크기가 충분히 작지 않으면 재귀 호출을 통해 다시 분할을 시작한다.
-
결합 : 정렬된 부분 배열을 하나의 배열에 결합시킨다.
mergeSort(A[], p, r) { if(p<r) then { q <- (p+r) / 2; mergeSort(A, p, q); mergeSort(A, q+1, r); merge(A, p, q, r); } } merge { i <- p; j <- q+1; t <- 1; while(i<=1 and j<= r) { if(A[i] <= A[j]) { then tmp[t++] <- A[i++]; } else { tmp[t++] <- A[j++]; } } while(i <= q) { tmp[t++] <- A[i++]; } while(j <= r) { tmp[t++] <- A[j++]; } i <- p; t <- 1; while(i <= r) { A[i++] <- tmp[t++]; } }각 요소에 접근하는 시간 O(n)과 각 배열을 다시 병합하는 O(logn) 시간이 필요하기 때문에 n * long n 의 시간이 된다.
-
-
O(2n) 지수 시간(exponential time)
보통 문제를 풀기 위해 모든 경우의 수를 판단할 때 사용된다.
이 모든 경우의 수의 집합을 멱집합(power set)이라고 하며 시간 복잡성이 상당히 높은 O(2n) 이기 때문에 최대한 피해야하는 알고리즘 유형이다.
-
O(n!) 팩토리얼 시간(Factorial Time)
7가지 함수 중 가장 시간이 많이 걸리는 경우이다.
다행히 특수한 경우에만 사용되기 때문에 문제를 겪을 일이 거의 없다.팩토리얼 시간은 외판원 문제(TSP, Traveling Salesman Problem)를 해결하는 방법 중 하나인 브루트 포스 탐색에서 걸리는 시간이다.
브루트 포스 탐색(brute force search)
뜻 그대로 무식한 힘으로 탐색하는 방식이다. 완전 탐색 알고리즘으로 가능한 모든 경우의 수를 모두 탐색하면서 요구 조건에 충족되는 결과만을 가져온다.이 알고리즘의 강력한 점은 예외없이 정답만을 출력하는 것이다.
-
모든 자료를 탐색해야 하기 때문에 특정한 구조를 전체적으로 탐색할 수 있는 방법을 필요로 한다.
-
가장 기본적인 접근 방법은 답이 존재할 것으로 예상되는 모든 영역을 전체 탐색하는 방법이다.
-
선형 구조를 전체적으로 탐색하는 순차 탐색, 비선형 구조를 전체적으로 탐색하는 깊이 우선 탐색(DFS, depth first search)와 너비 우선 탐색(BFS, breadth first search)이 가장 기본적인 도구이다.
-
빅 오메가(Big-Ω notation)
함수 f(n)과 g(n)이 모든 n ≥ n0 에서 f(n) ≥ c·g(n) 조건을 만족시키는 양의 상수 c > 0 와 양의 정수 n0 ≥ 0 이 존재한다면 f(n) ∈ Ω(g(n)) 또는 f(n) = Ω(g(n))로 쓸 수 있다.
빅 오에서 두 함수의 비교가 바뀐 경우이다.
빅 오메가는 f(n)이 항상 c·g(n) 보다 느린 경우만 존재하기 때문에 c·g(n)는 f(n)의 점근적 하한이 된다.
따라서 가장 빠른 경우 즉, 최상의 경우일 때 유요한 정보를 얻을 수 있다.
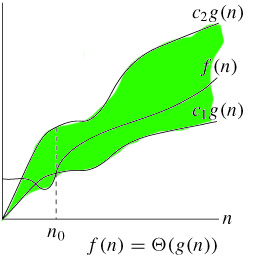
빅 세타(Big-Θ notation)
함수 f(n)과 g(n)이 c1·g(n) ≤ f(n) ≤ c2·g(n) 조건을 만족시키는 양의 상수 c1, c2 > 0 와 양의 정수 n0 ≥ 0 이 존재한다면 f(n) ∈ Θ(g(n)) 또는 f(n) = Θ(g(n))로 쓸 수 있다.
빅 오와 빅 오메가의 공통부분이다. 최상과 최악의 중간인 평균적인 복잡도를 뜻한다.
정리
빅 오는 최악의 경우 빅 오메가는 최상의 경우라고 꼭 정해진 것은 아니지만 점근적 상한과 점근적 하한이라는 특징을 가지고 있기 때문에 유효한 정보를 얻는 방법이 각 각 다른 것이다.
실제로 많이 쓰이는건 빅 오 이다. 아무래도 프로그래밍 특성상 극단적 상황에서 효율을 따지는게 더 중요한 상황이 많기 때문일 것이다.