
[영리한 프로그래밍을 위한 알고리즘] #9 정렬 알고리즘2
힙정렬(heap sort)
힙 또는 이진 힙(binary heap)의 자료구조를 이용해서 정렬을 하는 알고리즘이다.
-
최악의 경우 시간복잡도 O(nlogn)으로 빠른 성능을 보인다.
-
합병정렬의 경우에도 O(nlogn)의 성능이였지만 추가적으로 데이터를 저장할 임시 변수가 필요했지만 힙정렬은 추가 배열이 불필요하다.
-
이진 힙(binary heap) 자료구조를 사용한다.
힙의 정의
조건
완전 이진 트리(complete binary tree) 이면서 heap property를 만족해야한다.
정 이진 트리 vs 완전 이진 트리
-
정 이진 트리(full binary tree)
모든 레벨에 노드들이 꽉 차있는 이진트리 구조를 말한다.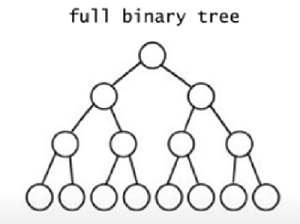
-
완전 이진 트리(complete binary tree)
마지막 레벨을 제외하면 완전히 꽉 차 있으며 마지막 레벨에는 가장 오른쪽 부터 연속된 몇 개의 노드가 비어있을 수 있다.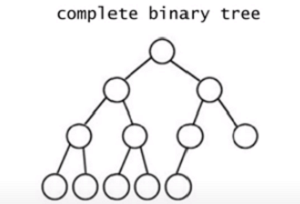
heap property 직역하면 힙속성이다. 이진 트리의 노드안의 값이 어떤 속성을 가지느냐에 따라서 종류가 나뉘어진다.
-
max heap property
부모는 자식보다 크거나 같다. -
min heap property
부모는 자식보다 작거나 같다.
max heap과 min heap 대칭적인 관계로 둘 중 하나의 heap에서 적용되는 알고리즘은 대소 관계만 바꾸어 다른 heap에도 사용이 가능한 본질적으로 같은 자료구조로 용도나 경우에 따라 사용이 다를 뿐이다.
heap 구조 살펴보기
heap sort를 다룰때 더 적합한 max heap을 다룬다.
-
완전 이진 트리 & max property
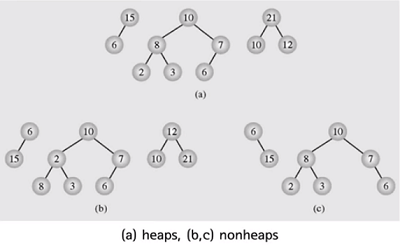
heap sort에 적합한 heap은 (a) 구조의 트리들이다.
(b)와 (c)의 경우 heap property를 만족하지 못하거나 완전 이진 트리가 아닌 경우의 트리들이 포함되어 있다.
-
동일한 데이터, 다른 구조
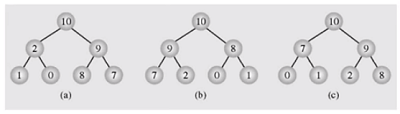
3개의 트리 모두 동일한 데이터를 저장하고 있지만 부모 자식의 구조가 전부 다르다. 즉 힙은 유일하지 않고 서로 다른 여러가지가 될 수 있다.
-
힙은 일차원 배열로 표현이 가능하다.
A[1 ... n] 힙이 있을 때 A[i]의 부모 = A[i / 2] A[i]의 왼쪽 자식 = A[2i] A[i]의 오른쪽 자식 = A[2i+1]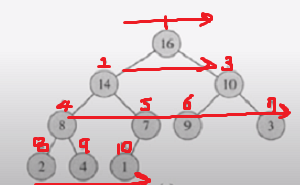
레벨 순, 같은 레벨일 때는 왼쪽 부터 넘버링을 한 다음 이 번호 순서대로 배열의 인덱스에 채워 주면 된다.
트리를 배열로 저장하게 되면 트리에서만 가지는 부모 자식관계의 정보를 알 수 없게 된다. 하지만 완전 이진 트리의 특징으로 각 레벨의 노드들을 넘버링할 때 규칙을 가지기 때문에 배열에서도 부모 자식 관계를 알 수 있게 된다.
max-heapify
힙 자료구조를 다루기 위해서 필요한 기본 연산으로 적용하려면 몇 가지 전제조건이 필요하다.
-
완전 이진 트리 구조이다.
-
왼쪽과 오른쪽 서브트리는 그 자체로 heap이다.
-
유일하게 루트만 heap property를 만족하지 않는다.
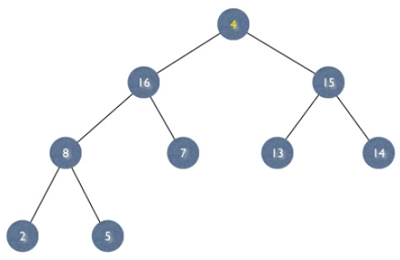
위 트리를 보면 왼쪽과 오른쪽 각 서브트리는 힙이며 루트가 자식보다 값이 작아 heap property를 만족하지 않는 상황이다.
따라서 루트까지 만족시키기 위해서는 루트의 값을 자식들과 교체해야한다.
-
두 자식들 중 더 큰 쪽이 부모보다 크면 교환하고 조건에 해당하는 자식이 없을 때 까지 동작을 반복하면 된다. 즉 두 자식이 자신보다 작거나 자신이 리프노드인 경우이다.
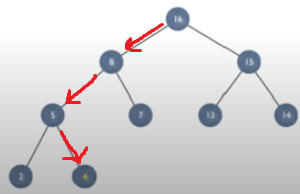
자식 노드와 위치가 교환이 되어도 이미 더 큰 숫자를 비교한 결과이기 때문에 반대쪽 노드는 신경을 쓰지 않아도 당연히 heap이 성립하게 된다.
-
max-heapify recursive
같은 동작을 반복하는 점을 통해 recursive가 가능하다는걸 알 수 있다.// A는 heap Max-Heapify(A, i) { if there is no child of A[i] return; k <- index of the diggest child of i; // 값비교 부모가 크면 완료 if A[i] >= A[k] return; // 아니면 자리 교체 exchange A[i] and A[k]; // 순환, 더 이상 다른쪽 노드는 고려안해도 됨, // k부터 시작 Max-Heapify(A, k); }heapify 알고리즘은 다음 레벨로 넘어갈 때마다 다른 한쪽의 노드는 모두 배제하게 되므로 어떤 경우에도 트리의 높이(h)보다 더 많은 시간이 필요하지 않게 된다.
따라서 max-heapify 알고리즘의 시간복잡도는 O(h) 이다.
또 트리의 높이는 Θ(logn) 로 표현이 가능하며 점근적 표현법에 따라서 비례관계인 h와 Θ(logn)를 이용해서 시간복잡도 O(h) = Θ(logn)로 표기할 수 있다.
힙 만들기
힙 정렬을 하기 위해서는 우선 힙으로 만들어야한다.
주어진 데이터가 배열에 저장되어 있다면 일단 완전 이진 트리로 해석한다. 직접 트리로 구현할 필요는 없고 배열의 구조를 트리라고 생각하면 된다. (완전 이진 트리는 배열로 변환이 가능하기 때문에)
이렇게 해석한 트리는 모양은 트리라도 데이터가 정렬되지 않았기 때문에 아직 heap이라고 볼 수는 없다.
완전 이진 트리의 데이터를 정렬한다.
Max-Heap(A)
// length는 정렬할 데이터의 개수 = n 이다.
heap-size[A] <- length[A]
// 반복마다 다른쪽의 노드는 배제하기 때문에 n / 2 이다.
for i <- length[A] / 2 down to 1
// 같은 동작 루트노드 옮겨서 반복
do Max-Heapify(A,i)
트리가 heap property를 충족하도록 데이터를 정렬시켜 힙으로 만든다.
노드를 확인할 때는 레벨 노드의 역순으로 오른쪽 부터 검사해서 리프노드가 아닌 노드를 찾아낸다.
그렇게 찾아낸 노드를 루트노드로 하는 서브트리를 확인한다.
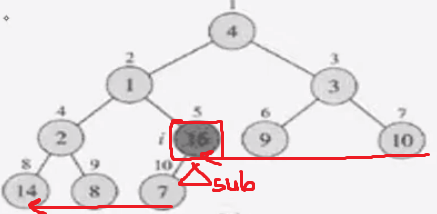
해당 노드가 완전 이진 트리라면 heapify를 진행한다.
위에서는 이미 부모노드가 자식보다 크기 때문에 아무일도 발생하지 않는다.
이 동작을 반복하여 진행하면 전체가 max-property를 만족하는 heap이 완성된다.
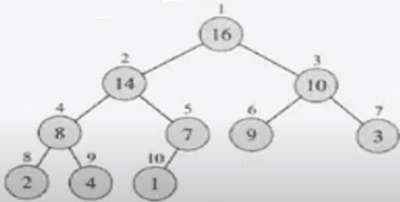
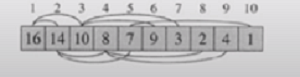
실제 데이터는 배열안에 16 14 10 8 7 9 3 2 4 1 순서로 저장되어있다.
시간복잡도
heapify를 실행하는데 logn이고 n / 2 반복하기 때문에 전체 시간복잡도는 다음과 같다.
\[\frac {n}{2}logn = O(nlogn)\]사실 위 결과는 대략적인 계산으로 구한것으로 heapify의 회수가 면밀히 따지만 전체 트리의 루트 노드에서만 logn이고 서브 트리들에서는 그보다 적기 때문에 더 정확히 계산했을 때 결과는
\[O(n)\]이라고 볼 수 있다.
힙 정렬하기
힙 구조는 정렬을 하기전에 이미 유리한 조건을 가지고 있다.
-
부모는 자식이 크다는 조건으로 데이터간의 관계를 알 수 있다.
-
최대값은 루트노드이다. (배열로 봤을 때 맨앞 인덱스)
1. 힙에서 최대값인 루트는 가장 마지막 값과 바꾼다.
2. 이제 자리가 확정된 마지막 값은 배제 시키고 힙의 크기를 1줄인다.
여전히 서브트리는 heap이지만 전체적으로는 루트의 값이 바뀌면서 heap이 깨지게 된다.
이 구조는 Max-Heapify를 통해서 다시 heap으로 만들 수 있다.
3. 다시 처음부터 동작을 반복한다.
수도코드
HeapSort(A)
Max-Heap(A) // O(n)
for i <- heap_size down to 2 do // n-1 time
exchange A[1] <-> A[i] // O(1)
heap_size <- heap_size - 1 // O(1)
Max-Heapify(A, 1) // O(logn)
// total time = O(nlogn)
정리
힙정렬을 사용하기 위해서는 우선 데이터 구조를 힙으로 만든다.
힙으로 만들 때는 완전 이진 트리 구조를 생각하고 heap property를 만족시키기 위해서 heapify를 실행한다.
이렇게 힙이 완성되었다면 루트노드는 항상 최대값이기 때문에 트리의 맨뒤에 배치하고 힙 크기에서 배제시킨다. 완전 이진 트리이기 때문에 마지막 (레벨 역순으로 오른쪽 부터) 부터 제거하여도 구조가 바뀌지 않는다. 하지만 노트의 값이 바뀌면서 heap property가 깨지게 되므로 다시 heapify를 실행시켜 준다.
여기서 반복되는 동작을 가지고 recursive로 만들어 실행시킨다.